
1. 硬件:
8171m*2;RTX3060-12G;RTX3080Ti-12G
2. 测试内容:
lammps,eam势,hcp-Ti(原子数:54000/128000/432000/1024000), fix npt驰豫
3. 环境
oneAPI-2022.0.1, cuda-11.6
4. 测试结果
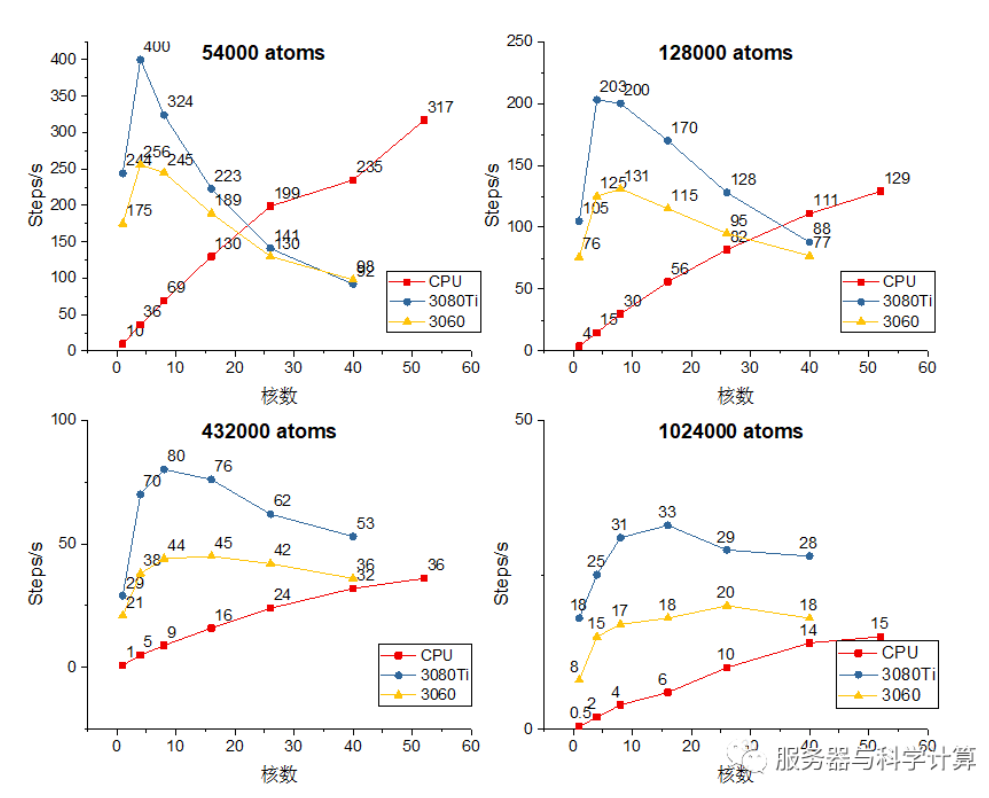
PS:横坐标为核数,双路8171m共52核;纵坐标为每秒计算的步数,数值越大越快。
不论原子数的多少,GPU加速的最佳核数都是8-16核。在每一步的计算过程中原子的坐标和力数据都在CPU和GPU之间来回移动,过多的核数会导致数据交流复杂度增加,进而造成CPU-CPU和CPU-GPU的通信延时。因而GPU加速时调用的核数并非越多越好,该测试中8-16核为最优核数。
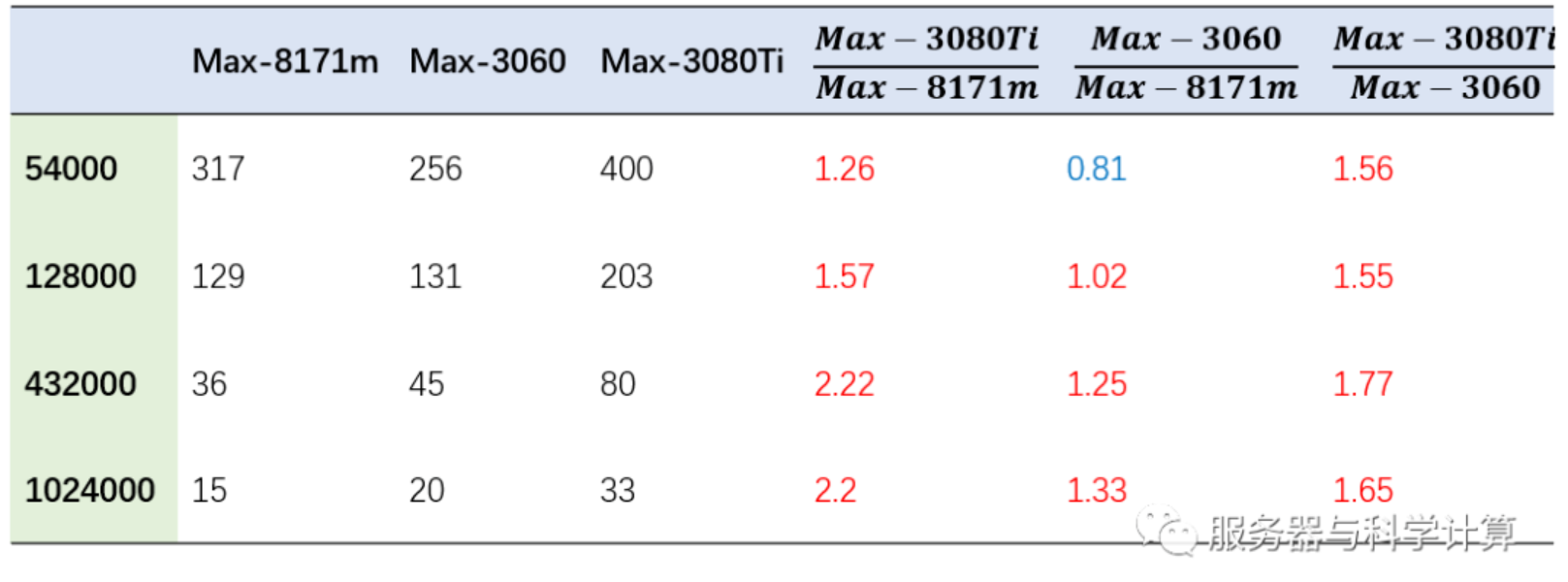
原子越多时,GPU的加速效果越明显。原子数54000,RTX3060加速效果反而低于52核8171m的满核速率。
高核数下,RTX3080Ti计算速度可达纯8171m速度的2倍;RTX3060大概是纯8171m的1.2倍;RTX3080Ti的加速效率大概是RTX3060的1.5-1.7倍。RTX3080Ti相比RTX3060具有更多的cuda核心数。
当我们使用GPU加速时,会有较多的cpu核数处于空闲状态,那么剩余的核数,可进行独立的纯CPU计算任务。比如我们可以同时进行两个计算任务:任务1调用8cores+GPU ;任务2调用 44cores。如此算来,那么GPU带来的计算效率提升更高。
GPU加速计算时,GPU的资源是显存,即显存满了,计算就会报错停止。MD计算中显存的占用与模型大小、调用核数、neighbor bin大小有关。因此,计算时我们需选用显存大的GPU。
目前lammps中依旧还有部分势函数不支持GPU加速,如常用的meam势。因此我们在购买服务器时,需充分了解自己的计算的前提下进行显卡的选择。



 15010805977
15010805977
 15010876190
15010876190
