可以看出不使用连接池的话,为了执行一条 SQL,会花很多时间在安全认证、网络IO上。
如果使用连接池,执行一条 SQL 就省去了建立连接和断开连接所需的额外开销。
还能想起哪里用到了连接池的思想吗?我认为 HTTP 长链接也算一个变相的链接池,虽然它本质上只有一个连接,但是思想却和连接池不谋而合,都是为了复用同一个连接发送多个 HTTP 请求,避免建立和断开连接的开销。
池化实际上是预处理和延后处理的一种应用场景,通过池子将各类资源的创建提前和销毁延后。
四、同步变异步
对于处理耗时的任务,如果采用同步的方式,那么会增加任务耗时,降低系统并发度。
可以通过将同步任务变为异步进行优化。
举个例子,比如我们去 KFC 点餐,遇到排队的人很多,当点完餐后,大多情况下我们会隔几分钟就去问好了没,反复去问了好几次才拿到,在这期间我们也没法干活了,这时候我们是这样的:
 同步写法
同步写法
这个就叫同步轮训, 这样效率显然太低了。
服务员被问烦了,就在点完餐后给我们一个号码牌,每次准备好了就会在服务台叫号,这样我们就可以在被叫到的时候再去取餐,中途可以继续干自己的事。
这就叫异步,在很多编程语言中有异步编程的库,比如 C++ std::future、Python asyncio 等,但是异步编程往往需要回调函数(Callback function),如果回调函数的层级太深,这就是回调地狱(Callback hell)。回调地狱如何优化又是一个庞大的话题。。。。
这个例子相当于函数调用的异步化,还有的是情况是处理流程异步化,这个会在接下来消息队列中讲到。
五、消息队列
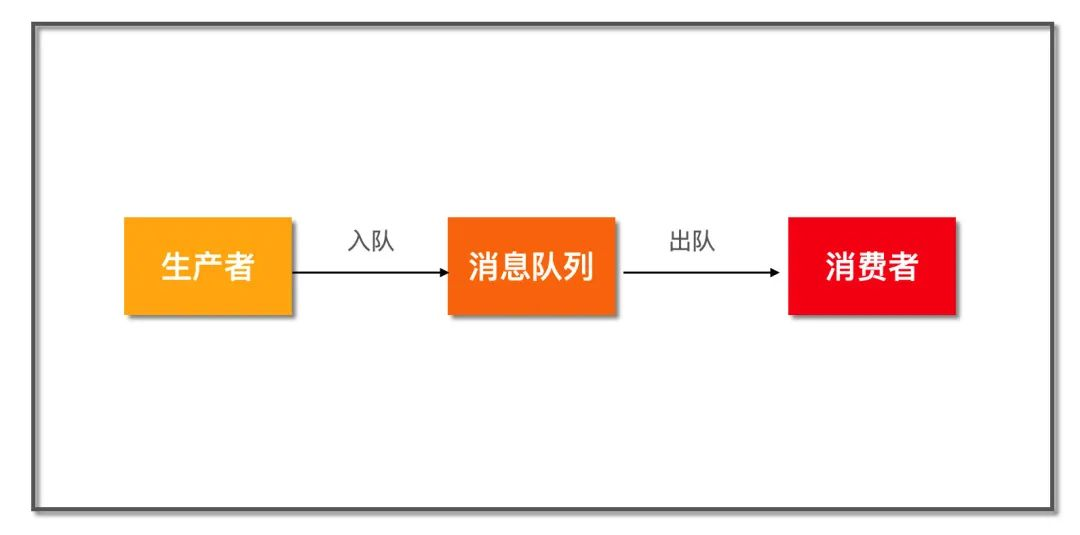 消息队列示意图
消息队列示意图
这是一个非常简化的消息队列模型,上游生产者将消息通过队列发送给下游消费者。在这之间,消息队列可以发挥很多作用,比如:
5.1 服务解耦
有些服务被其它很多服务依赖,比如一个论坛网站,当用户成功发布一条帖子有一系列的流程要做,有积分服务计算积分,推送服务向发布者的粉丝推送一条消息..... 对于这类需求,常见的实现方式是直接调用:
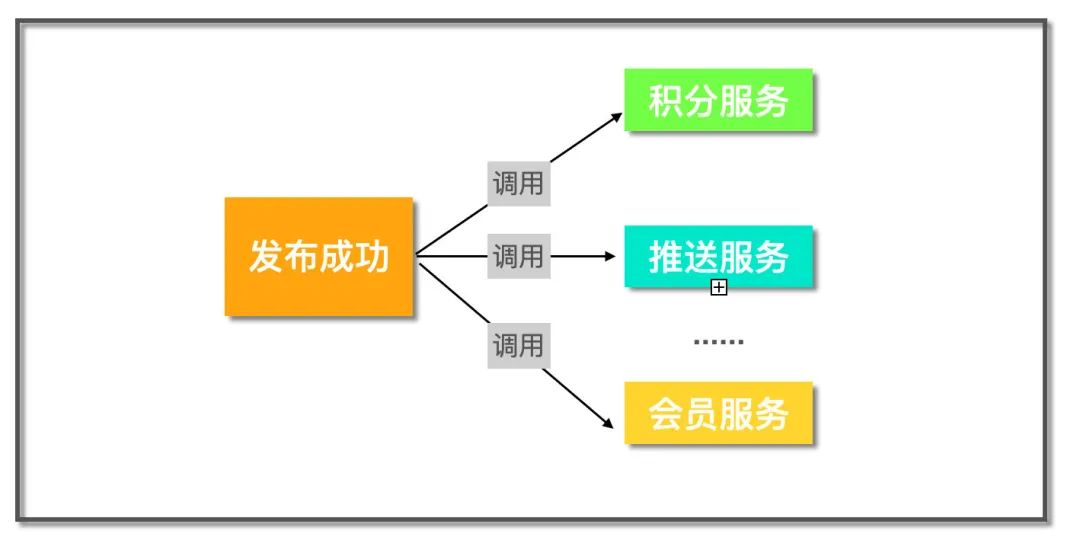 直接调用
直接调用
这样如果需要新增一个数据分析的服务,那么又得改动发布服务,这违背了依赖倒置原则,即上层服务不应该依赖下层服务,那么怎么办呢?
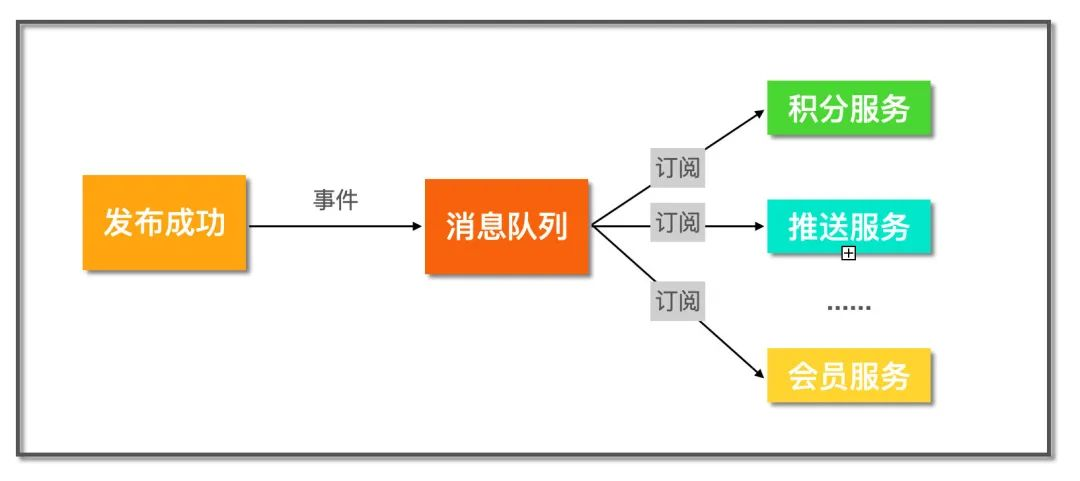 发布订阅模式
发布订阅模式
引入消息队列作为中间层,当帖子发布完成后,发送一个事件到消息队列里,而关心帖子发布成功这件事的下游服务就可以订阅这个事件,这样即使后续继续增加新的下游服务,只需要订阅该事件即可,完全不用改动发布服务,完成系统解耦。
5.2 异步处理
有些业务涉及到的处理流程非常多,但是很多步骤并不要求实时性。那么我们就可以通过消息队列异步处理。比如淘宝下单,一般包括了风控、锁库存、生成订单、短信/邮件通知等步骤。但是核心的就风控和锁库存, 只要风控和扣减库存成功,那么就可以返回结果通知用户成功下单了。后续的生成订单,短信通知都可以通过消息队列发送给下游服务异步处理。大大提高了系统响应速度。
这就是处理流程异步化。
5.3 流量削峰
一般像秒杀、抽奖、抢卷这种活动都伴随着短时间海量的请求, 一般超过后端的处理能力,那么我们就可以在接入层将请求放到消息队列里,后端根据自己的处理能力不断从队列里取出请求进行业务处理。
就像最近长江汛期,上游短时间大量的洪水汇聚直奔下游,但是通过三峡大坝将这些水缓存起来,然后匀速的向下游释放,起到了很好的削峰作用。
起到了平均流量的作用。
5.4 总结
消息队列的核心思想就是把同步的操作变成异步处理,异步处理会带来相应的好处,比如:
但是软件开发没有银弹,所有的方案选择都是一种 trade-off。 同样,异步处理也不全是好处,也会导致一些问题:
六、批量处理
在涉及到网络连接、IO等情况时,将操作批量进行处理能够有效提高系统的传输速率和吞吐量。
在前后端通信中,通过合并一些频繁请求的小资源可以获得更快的加载速度。
比如我们后台 RPC 框架,经常有更新数据的需求,而有的数据更新的接口往往只接受一项,这个时候我们往往会优化下更新接口,
使其能够接受批量更新的请求,这样可以将批量的数据一次性发送,大大缩短网络 RPC 调用耗时。
七、数据库
我们常把后台开发调侃为「CRUD」,数据库在整个应用开发过程中的重要性不言而喻。
而且很多时候系统的瓶颈也往往处在数据库这里,慢的原因也有很多,比如可能是没用索引、没用对索引、读写锁冲突等等。
那么如何使用数据才能又快又好呢?下面这几点需要重点关注:
7.1 索引
索引可能是我们平时在使用数据库过程中接触得最多的优化方式。索引好比图书馆里的书籍索引号,想象一下,如果我让你去一个没有书籍索引号的图书馆找《人生》这本书,你是什么样的感受?当然是怀疑人生,同理,你应该可以理解当你查询数据,却不用索引的时候数据库该有多崩溃了吧。
数据库表的索引就像图书馆里的书籍索引号一样,可以提高我们检索数据的效率。索引能提高查找效率,可是你有没有想过为什么呢?这是因为索引一般而言是一个排序列表,排序意味着可以基于二分思想进行查找,将查询时间复杂度做到 O(log(N)),快速的支持等值查询和范围查询。
二叉搜索树查询效率无疑是最高的,因为平均来说每次比较都能缩小一半的搜索范围,但是一般在数据库索引的实现上却会选择 B 树或 B+ 树而不用二叉搜索树,为什么呢?
这就涉及到数据库的存储介质了,数据库的数据和索引都是存放在磁盘,并且是 InnoDB 引擎是以页为基本单位管理磁盘的,一页一般为 16 KB。AVL 或红黑树搜索效率虽然非常高,但是同样数据项,它也会比 B、B+ 树更高,高就意味着平均来说会访问更多的节点,即磁盘IO次数!
“根据 Google 工程师 Jeff Dean 的统计,访问内存数据耗时大概在 100 ns,访问磁盘则是 10,000,000 ns。
”
所以表面上来看我们使用 B、B+ 树没有 二叉查找树效率高,但是实际上由于 B、B+ 树降低了树高,减少了磁盘 IO 次数,反而大大提升了速度。
这也告诉我们,没有绝对的快和慢,系统分析要抓主要矛盾,先分析出决定系统瓶颈的到底是什么,然后才是针对瓶颈的优化。
其实关于索引想写的也还有很多,但还是受限于篇幅,以后再单独写。
先把我认为索引必知必会的知识列出来,大家可以查漏补缺:
7.2 读写分离
一般业务刚上线的时候,直接使用单机数据库就够了,但是随着用户量上来之后,系统就面临着大量的写操作和读操作,单机数据库处理能力有限,容易成为系统瓶颈。
由于存在读写锁冲突,并且很多大型互联网业务往往读多写少,读操作会首先成为数据库瓶颈,我们希望消除读写锁冲突从而提升数据库整体的读写能力。
那么就需要采用读写分离的数据库集群方式,一主多从,主库会同步数据到从库。写操作都到主库,读操作都去从库。
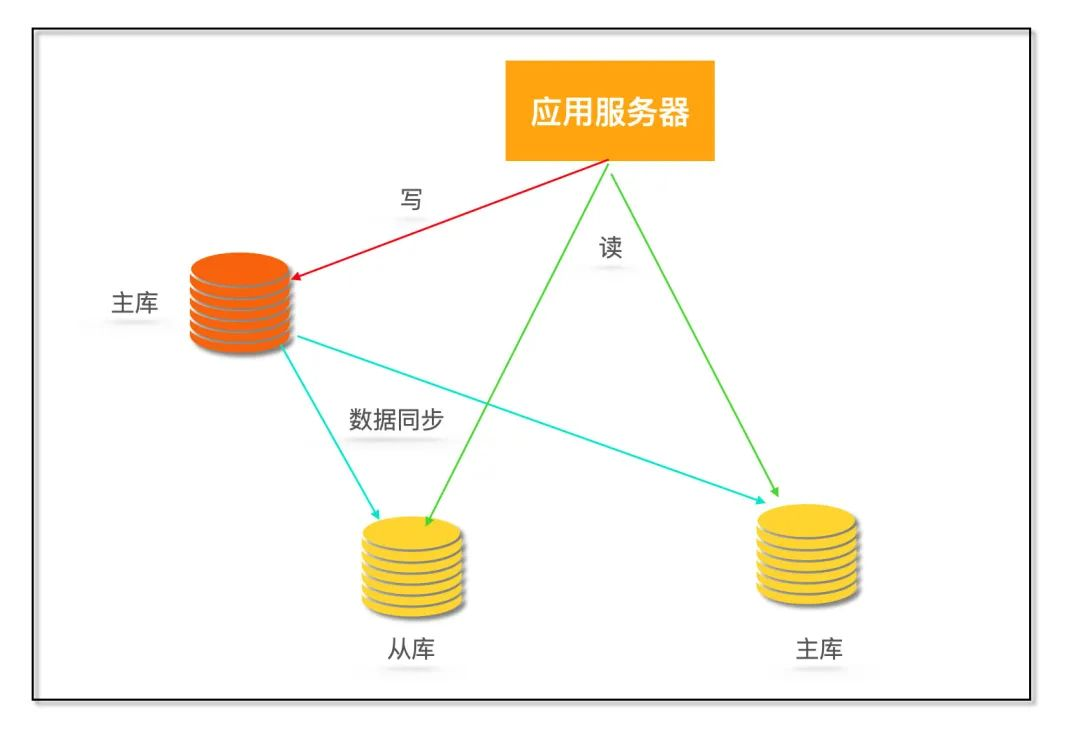 读写分离
读写分离
读写分离到之后就避免了读写锁争用,这里解释一下,什么叫读写锁争用:
MySQL 中有两种锁:
读写分离解决问题的同时也会带来新问题,比如主库和从库数据不一致
MySQL 的主从同步依赖于 binlog,binlog(二进制日志)是 MySQL Server 层维护的一种二进制日志,是独立于具体的存储引擎。它主要存储对数据库更新(insert、delete、update)的 SQL 语句,由于记录了完整的 SQL 更新信息,所以 binlog 是可以用来数据恢复和主从同步复制的。
从库从主库拉取 binlog 然后依次执行其中的 SQL 即可达到复制主库的目的,由于从库拉取 binlog 存在网络延迟等,所以主从数据存在延迟问题。
那么这里就要看业务是否允许短时间内的数据不一致,如果不能容忍,那么可以通过如果读从库没获取到数据就去主库读一次来解决。
7.3 分库分表
如果用户越来越多,写请求暴涨,对于上面的单 Master 节点肯定扛不住,那么该怎么办呢?多加几个 Master?不行,这样会带来更多的数据不一致的问题,增加系统的复杂度。那该怎么办?就只能对库表进行拆分了。
常见的拆分类型有垂直拆分和水平拆分。
考虑拼夕夕电商系统,一般有 订单表、用户表、支付表、商品表、商家表等, 最初这些表都在一个数据库里。后来随着砍一刀带来的海量用户,拼夕夕后台扛不住了! 于是紧急从阿狸粑粑那里挖来了几个 P8、P9 大佬对系统进行重构。
分库分表同时会带来一些问题,比如平时单库单表使用的主键自增特性将作废,因为某个分区库表生成的主键无法保证全局唯一,这就需要引入全局 UUID 服务了。
经过一番大刀阔斧的重构,拼夕夕恢复了往日的活力,大家又可以愉快的在上面互相砍一刀了。
(分库分表会引入很多问题,并没有一一介绍,这里只是为了讲解什么是分库分表)
八、具体技法
8.1 零拷贝
高性能的服务器应当避免不必要数据复制,特别是在用户空间和内核空间之间的数据复制。 比如 HTTP 静态服务器发送静态文件的时候,一般我们会这样写:
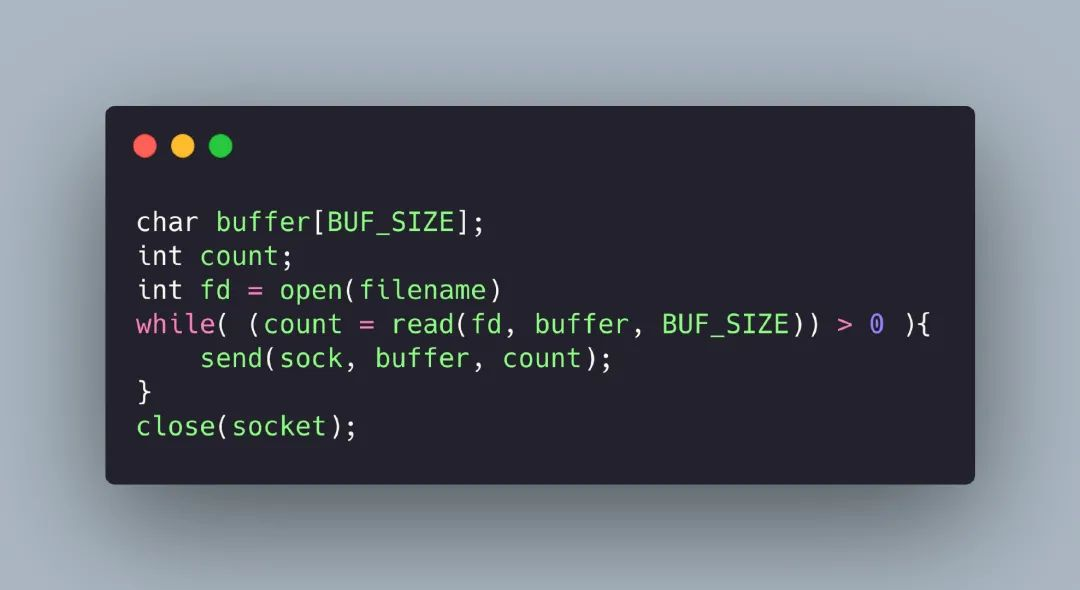 发送文件
发送文件
如果了解 Linux IO 的话就知道这个过程包含了内核空间和用户空间之间的多次拷贝:
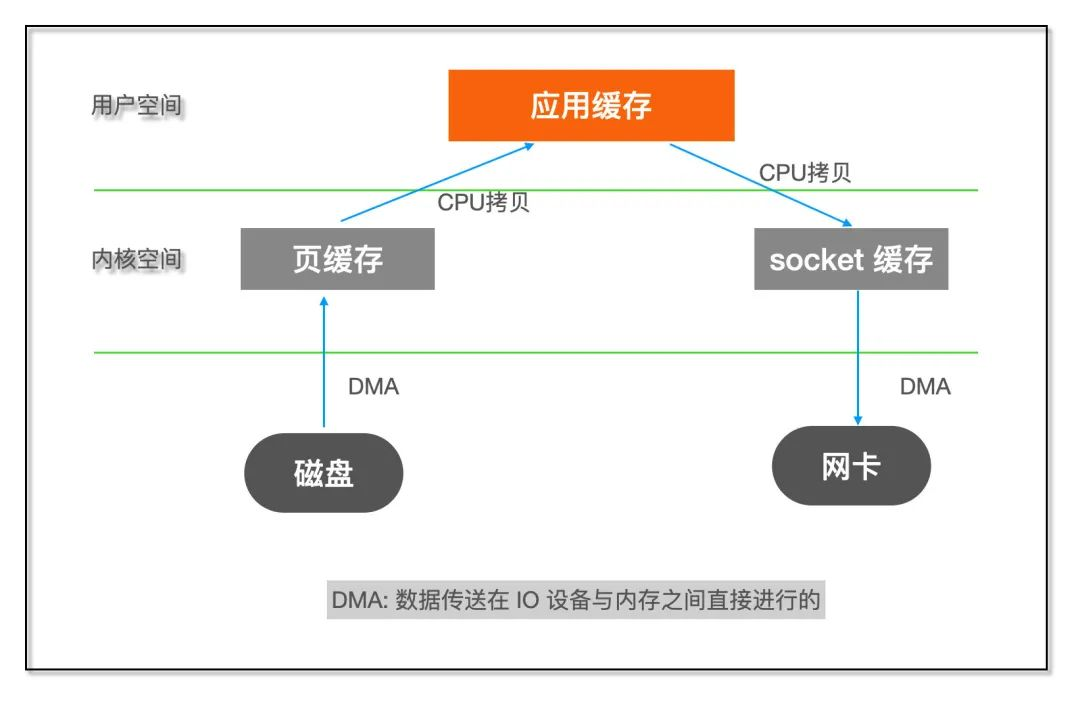 IO示意图
IO示意图
内核空间和用户空间之间数据拷贝需要 CPU 亲自完成,但是对于这类数据不需要在用户空间进行处理的程序来说,这样的两次拷贝显然是浪费。什么叫 「不需要在用户空间进行处理」?
比如 FTP 或者 HTTP 静态服务器,它们的作用只是将文件从磁盘发送到网络,不需要在中途对数据进行编解码之类的计算操作。
如果能够直接将数据在内核缓存之间移动,那么除了减少拷贝次数以外,还能避免内核态和用户态之间的上下文切换。
而这正是零拷贝(Zero copy)干的事,主要就是利用各种零拷贝技术,减少不必要的数据拷贝,将 CPU 从数据拷贝这样简单的任务解脱出来,让 CPU 专注于别的任务。
常用的零拷贝技术:
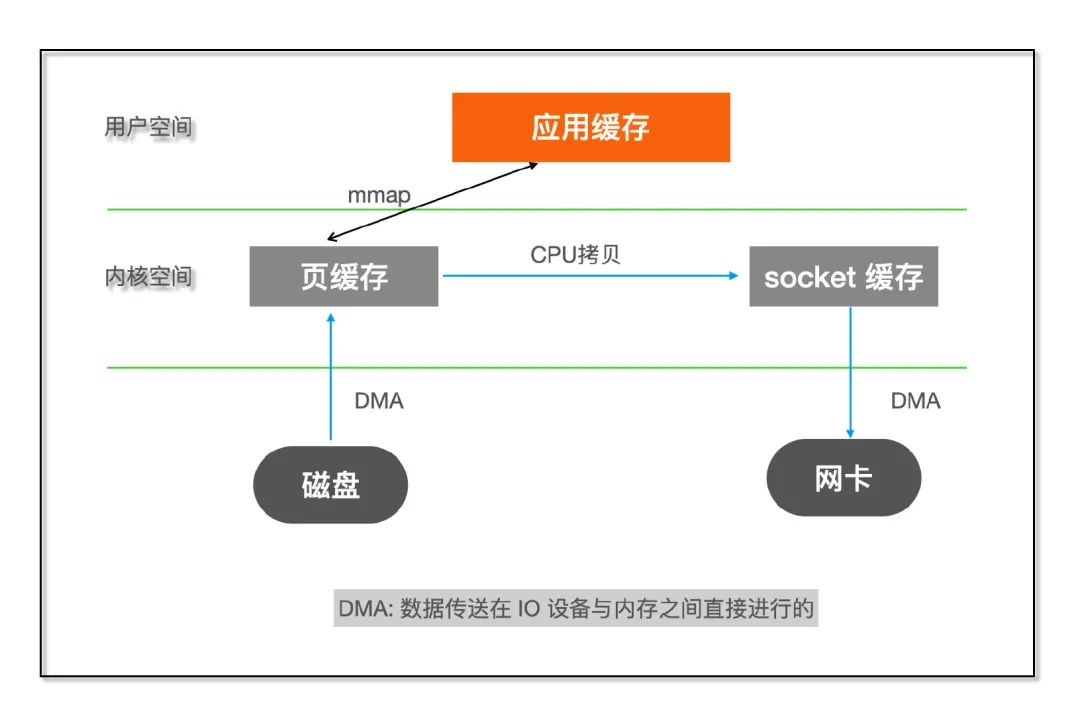 mmap
mmap
8.2 无锁化
在多线程环境下,为了避免 竞态条件(race condition), 我们通常会采用加锁来进行并发控制,锁的代价也是比较高的,锁会导致上线文切换,甚至被挂起直到锁被释放。
基于硬件提供的原子操作 CAS(Compare And Swap) 实现一些高性能无锁的数据结构,比如无锁队列,可以在保证并发安全的情况下,提供更高的性能。
首先需要理解什么是 CAS,CAS 有三个操作数,内存里当前值M,预期值 E,修改的新值 N,CAS 的语义就是:
如果当前值等于预期值,则将内存修改为新值,否则不做任何操作。
用 C 语言来表达就是:
 CAS
CAS
注意,上面 CAS 函数实际上是一条原子指令,那么是如何用的呢?
假设我需要实现这样一个功能:
对一个全局变量 global 在两个不同线程分别对它加 100 次,这里多线程访问一个全局变量存在 race condition,所以我们需要采用线程同步操作,下面我分别用锁和CAS的方法来实现这个功能。
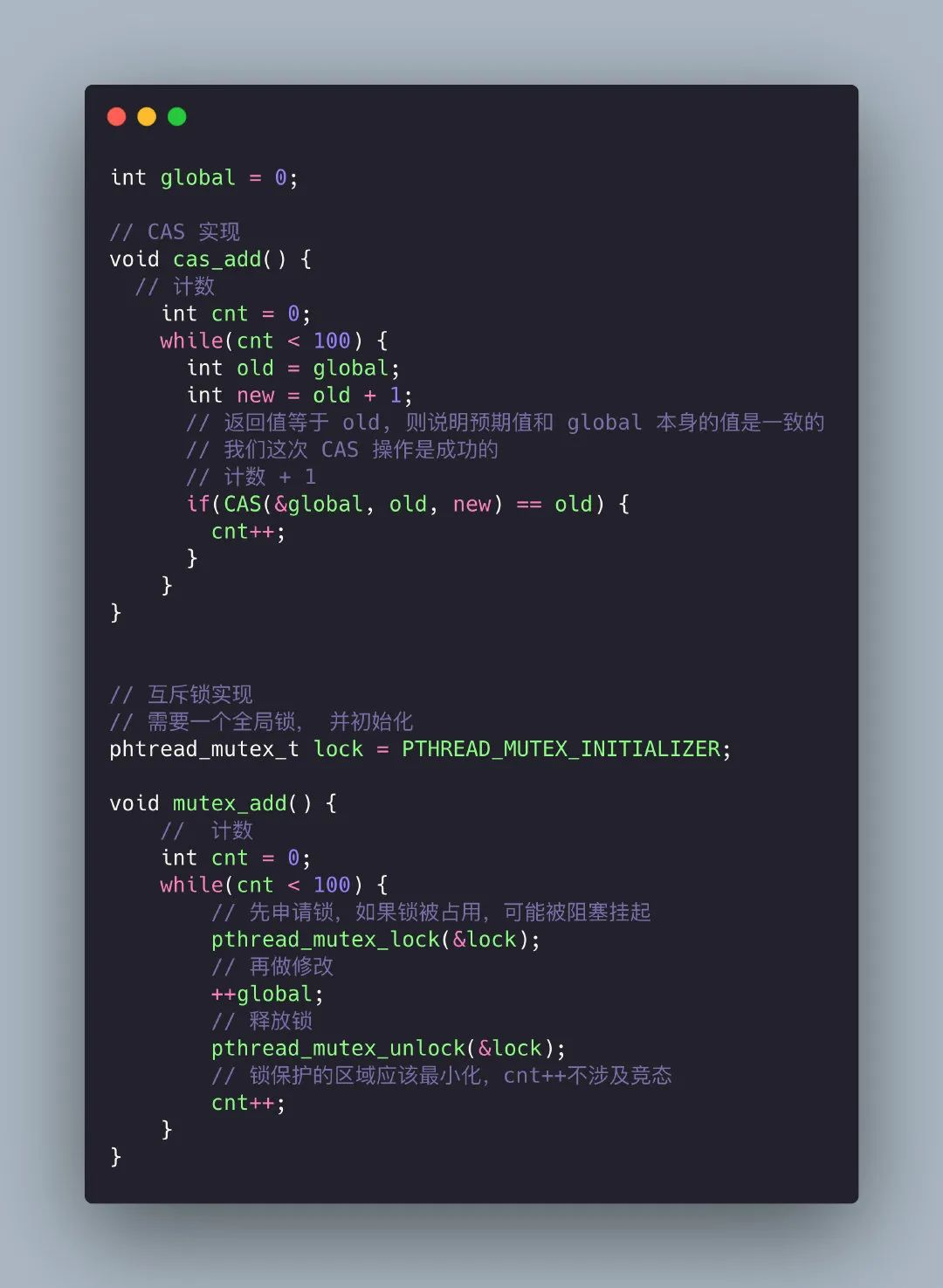 CAS和锁示范
CAS和锁示范
通过使用原子操作大大降低了锁冲突的可能性,提高了程序的性能。
除了 CAS,还有一些硬件原子指令:
8.3 序列化与反序列化
先看看维基百科怎么定义的序列化:
“In computing, serialization (US spelling) or serialisation (UK spelling) is the process of translating a data structure or object state into a format that can be stored (for example, in a file or memory data buffer) or transmitted (for example, across a computer network) and reconstructed later (possibly in a different computer environment). When the resulting series of bits is reread according to the serialization format, it can be used to create a semantically identical clone of the original object. For many complex objects, such as those that make extensive use of references, this process is not straightforward. Serialization of object-oriented objects does not include any of their associated methods with which they were previously linked.
”
我相信你大概率没有看完上面的英文描述,其实我也不爱看英文资料,总觉得很慢,但是计算机领域一手的学习资料都是美帝那边的,所以没办法,必须逼自己去试着读一些英文的资料。
实际上也没有那么难,熟悉常用的几百个专业名词,句子都是非常简单的一些从句。没看的话,再倒回去看看?
这里我就不做翻译了,主要是水平太低,估计做到「信达雅」的信都很难。
扯远了,还是回到序列化来。
所有的编程一定是围绕数据展开的,而数据呈现形式往往是结构化的,比如结构体(Struct)、类(Class)。 但是当我们 通过网络、磁盘等传输、存储数据的时候却要求是二进制流。 比如 TCP 连接,它提供给上层应用的是面向连接的可靠字节流服务。那么如何将这些结构体和类转化为可存储和可传输的字节流呢?这就是序列化要干的事情,反之,从字节流如何恢复为结构化的数据就是反序列化。
序列化解决了对象持久化和跨网络数据交换的问题。
序列化一般按照序列化后的结果是否可读,可分为以下两类:
还有 Java 、Go 这类语言内置了序列化方式,比如在 Java 里实现了 Serializable 接口即表示该对象可序列化。
说到这让我想起了大一写的的两个程序,一个是用刚 C 语言写的公交管理系统,当时需要将公交线路、站点信息持久化保存,当时的方案就是每个公交线路写在一行,用 "|"分割信息,比如:
第一列就是线路编号、第二项是发车时间、后面就是途径的站点。是不是非常原始?实际上这也是一种序列化方式,只是效率很低,也不通用。而且存在一个问题就是如果信息中包含 “|”怎么办?当然是用转义。
第二个程序是用 Java 写的网络五子棋,当时需要通过网络传输表示棋子位置的对象,查了一圈最后发现只需要实现 Serializable 接口,自己什么都不用干,就能自己完成对象的序列化,然后通过网络传输后反序列化。当时哪懂得这就叫序列化,只觉得牛逼、神奇!
最后完成了一个可以网络五子棋,拉着隔壁室友一起玩。。。真的是成就感满满哈哈哈。
说来在编程方面,已经很久没有这样的成就感了。





 15010805977
15010805977
 15010876190
15010876190
