



英特尔 HPC 路线图
此外,英特尔还分享了有关 Falcon Shores XPU 的更多详细信息,该芯片将具有不同数量的 x86 内核、GPU 内核和内存,具有令人眼花缭乱的可能配置。英特尔计划将其 CPU 和 GPU 产品线合并到这个单一的可组合产品中,并在 2024 年将这两个产品线合并为一个产品线。
我们现在还拥有英特尔配备 HBM 的 Sapphire Rapids 服务器芯片的第一个基准测试,它们正在进入市场以与 AMD 抗衡Milan-X处理器。英特尔声称,这些芯片在内存吞吐量受限的应用中提供的性能是其 Ice Lake Xeon 前代产品的三倍。
实现英特尔的 Zettascale 目标需要一系列进步,其中许多是革命性的,今天,该公司还分享了一些近期目标,同时还通过 Zettascale 构建模块路线图勾勒出更广泛的长期计划。让我们深入了解该公告。
正如我们在上面看到的,虽然 Ponte Vecchio 设计由 16 个计算块(tile)组成,这些块排列在芯片中心的两个库中,每个块有 8 个内核,而 Rialto Bridge 只有 8 个较长的块(大概)有 20 个 Xe 内核每一个都标志着重大的设计转变。
我们还看到,Ponte Vecchio 的 Rambo Cache tiles已被移除,但内核两侧仍有 8 个未知flavor的 HBM tiles,而芯片封装的相对角落则排列了两个 Xe Link tiles。为了帮助说明差异,上述相册中的最后六张图片包括当前一代 Ponte Vecchio 设计的框图。
Rialto Bridge 带有一个较新的未指定的工艺节点,但英特尔尚未指定哪些组件将得到升级(推测,所有组件都将迁移到较新的节点)。目前,英特尔将其“Intel 7”节点用于 Ponte Vecchio 的基本块和缓存,台积电 5nm 用于计算块,台积电 7nm 用于 Xe Link 块。
Rialto Bridge 还带有未指定的架构增强功能,类似于“tick”,与 Ponte Vecchio 相比,应用程序的性能提升高达 30%。英特尔尚未提供任何基准来支持这些说法,我们不确定如果这些改进是在相同的时钟/功率范围内。但是,30% 的预测与核心数量增加 25% 密切相关,这意味着我们不会看到实质性的 IPC 改进。
英特尔列出了 Rialto Bridge 的峰值功耗为 800W,比Ponte Vecchio的 600W 峰值有所增加,并将以开放式加速器模块 (OAM) 形式提供。英特尔表示将采用 OAM 2.0 规范,不过它还将继续提供其他形式的 GPU。Rialto Bridge 将与 Ponte Vecchio 封装兼容,因此可以直接升级。
此外,该公司将很快推出其 XPU Manager,这是一款适用于其数据中心 GPU 的开源监控和管理软件,可在本地和远程使用。否则,英特尔只会分享有关这款新 GPU 的模糊细节,使用诸如“更多 FLOPs”、“增加 I/O 带宽”和“更多 GT/s”之类的声明,这些声明并没有让我们对新设计有任何了解。然而,该公司确实在幻灯片中包含了 IDM 2.0 列表,表明它将继续使用代工合作伙伴来生产一些 Rialto Bridge tiles。不过,我们肯定会很快了解更多信息——英特尔表示,Rialto Bridge 将于 2023 年问世。

这种分解的芯片设计将具有单独的 x86 计算和 GPU 内核块,但英特尔可以使用这些块来创建这两种添加剂的任何混合物,例如全 CPU 模型、全 GPU 模型或两者的混合比例. 英特尔没有具体说明,但期望 x86 核心块可以有自己的性能核心 (P-core) 和效率核心 (E-core) 的混合也是可行的,或者我们可以看到 P- 和 E 集群-核心部署为自己的完整瓷砖。英特尔指出,这些tile将在未指定的Angstrom 时代工艺节点上制造,尽管英特尔的 20A 似乎符合它自己可以制造的tile的要求。
Falcon Shores 将配备更小的tile,用于各种flavor的 HBM 内存和网络additives。CPU、GPU、内存和网络功能的灵活比例将使英特尔能够在设计过程后期针对特定或新兴工作负载快速调整其 Falcon Shores SKU,这是一个重要的考虑因素,因为 AI/ML 领域的格局瞬息万变. 英特尔尚未具体说明是否允许客户混合和匹配以创建他们自己喜欢的tile混合,但这将非常适合该公司的英特尔代工服务 (IFS) 方法,该方法将看到它许可自己的 IP 并且还为其他公司制造芯片。不难想象,如果资金合适,其他类型的块,如 FPGA 或 ASIC,会在设计中发挥作用。
上述幻灯片展示了四tile设计与 x86 计算核心和 Xe GPU 核心的各种组合,以及四个可能容纳内存和网络芯片的较小块。
自然地,这种设计将允许英特尔利用其 IDM 2.0 模型,从而为某些功能生产一些自己的块,同时还与第三方晶圆厂和 IP 供应商签订合同,以混合和匹配的方式提供一些块,可以回避任何其自身的埃级工艺节点技术或其供应商的潜在制造问题。此外,在这里利用小芯片的UCIe 生态系统可能被证明是一个基石,使英特尔能够访问业界必须提供的最佳内存和网络添加剂。
英特尔将利用下一代先进封装在将融合成一个有凝聚力的单元的块之间提供“极端”带宽。然而,目前尚不清楚这些芯片是否会在下面有一个(活动的?)中介层,就像我们在 3D 堆叠的 Foveros 芯片中看到的那样,或者英特尔将使用哪种风格的互连技术来连接这些tile。英特尔在封装技术上投入巨资,并希望能在这里获得回报。
Falcon Shores 将拥有一个简化的编程模型,英特尔称该模型将创建一种“类似 CPU”的编程体验,大概基于该公司的 OneAPI 产品组合。英特尔预计该产品将于 2024 年上市。
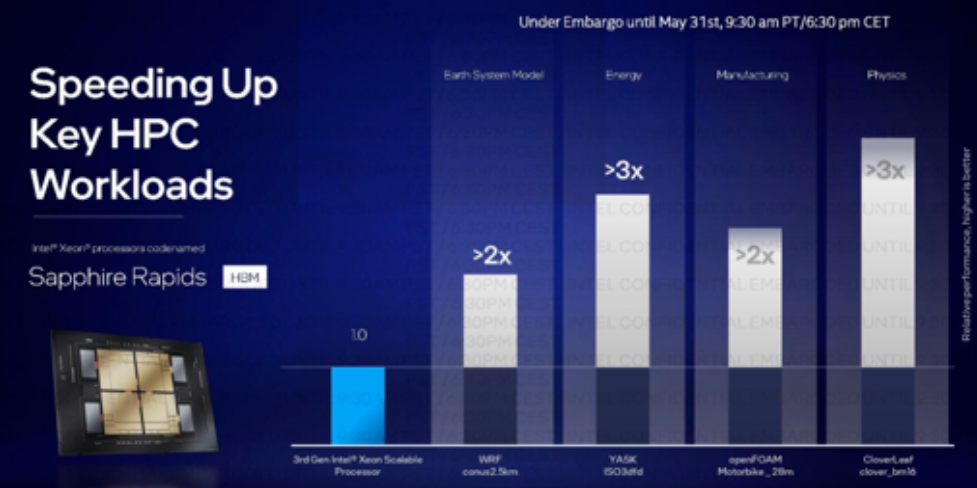
其他亮点包括声称在 YASK 能源基准中提高了 3 倍以上,OpenFOAM 提高了 2 倍,CloverLeaf Euler 求解器提高了 3 倍以上。英特尔还声称 Ansys 的 Fluent 软件速度提高了 2 倍,ParSeNet 提高了 2 倍。
英特尔表示,其配备 HBM 的 Sapphire Rapids 将于今年上市。标准的 Sapphie Rapids 模型尚未进入一般市场,所以这可能是冒险的。
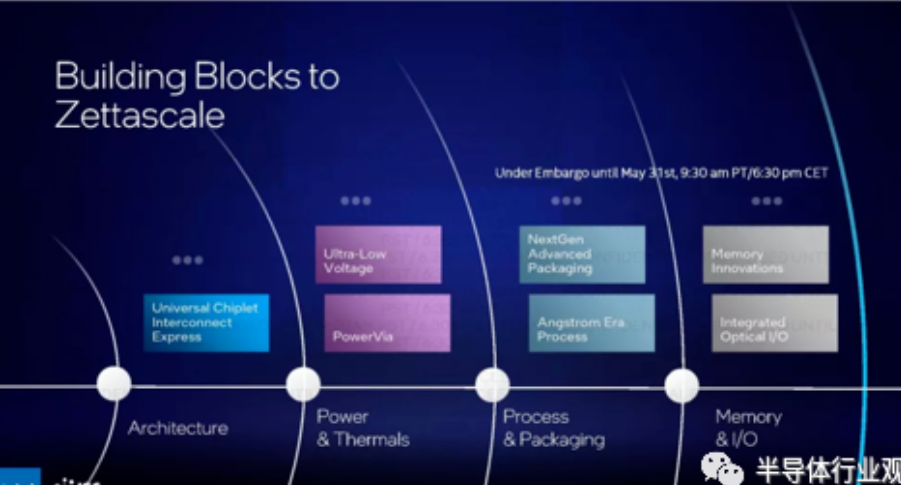
英特尔列出了它认为达到下一个计算水平所需的一些进步,即通用芯片互连高速 (UCIe)规格是其中最主要的。UCIe 旨在通过开源设计标准化小芯片之间的芯片到芯片互连,从而降低成本并培育更广泛的经过验证的小芯片生态系统。此外,UCIe 标准旨在与其他连接标准(如 USB、PCIe 和 NVMe)一样普遍,同时为小芯片连接提供卓越的功率和性能指标。这种互连使英特尔能够访问业界必须提供的最佳 IP,无论是在网络、内存或其他添加剂方面。
一些未来的超级计算机可能需要模块化核反应堆来满足他们对电力的巨大需求,因此说功耗是一个问题是一种严重的轻描淡写。英特尔还计划扩展其超低电压技术,该技术在其比特币挖矿 Blockscale ASIC可将时钟负载电压降低 50%,从而大幅降低功耗。这将降低高性能芯片的功耗,最终降低热负荷并简化冷却。英特尔的 PowerVia 技术为晶体管提供背面供电,是另一项重大进步。
英特尔正在探索新的存储器,以在更小的封装中提供更高的吞吐量,并设想将光学互连引入封装以帮助应对带宽增加。光网络可用于芯片到芯片和芯片到芯片的链路,更不用说在联网场景中开箱即用了。英特尔的 Xe Link 可以转向光互连,以提高带宽、带宽密度并降低功耗。英特尔要实现到 2027 年提供 Zettascale 计算能力的目标,需要所有这些因素以及更多因素。



 15010805977
15010805977
 15010876190
15010876190
