AMD 在其 2022 年金融分析师日分享了新的核心路线图,概述了其到 2024 年的预计架构和工艺节点增强。该路线图包括基于 Zen 4 架构的 5nm 和 4nm CPU,以及基于 Zen 5 架构的 4nm 和 3nm 处理器。
此外,AMD 还透露了有关将于 2024 年上市的 3nm Zen 5 芯片的一些初步细节,并分享了有关新的第四代 AMD Infinity 架构的细节。
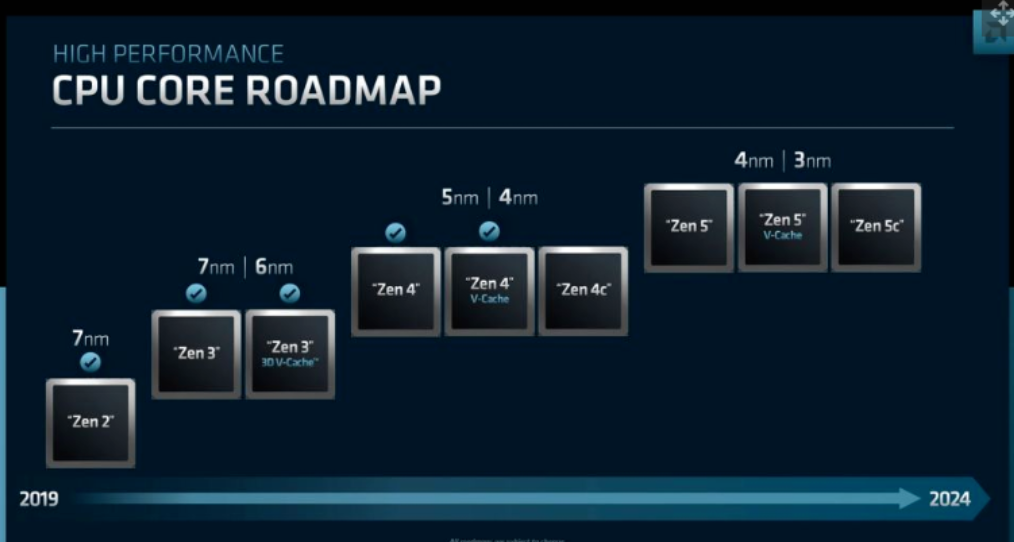 AMD 的 CPU 核心路线图并没有具体到年份,而是给了我们从 2019 年到 2024 年底的范围。Zen 4 芯片将在今年年底前出货,因此我们可以假设上述路线图的 Zen 4 部分2022 年开始。
AMD 的 CPU 核心路线图并没有具体到年份,而是给了我们从 2019 年到 2024 年底的范围。Zen 4 芯片将在今年年底前出货,因此我们可以假设上述路线图的 Zen 4 部分2022 年开始。
展望未来,AMD 的核心将分为三种类型:仅列为“Zen 4”的标准核心、配备 3D V-Cache 的核心和“Zen 4c”密度优化核心。Zen 4 将采用已经宣布的 5nm 变体,但我们也会看到 4nm 内核。这些 4nm Zen 4 内核可以作为所有芯片的广泛更新一代,或者 AMD 可以选择仅将 4nm 用于某些类别的芯片,正如我们在 7nm Zen 3 Ryzen 台式电脑型号和 6nm Zen 3 Ryzen 移动处理器中看到的那样。
同样的规则适用于 Zen 5 内核:AMD 将 Zen 5 内核分为标准、3D V-Cache 和“Zen 5c”变体。Zen 5 时代将采用 4nm 工艺首次亮相,可能来自台积电,并且还将提供 3nm 变体,尽管它们的到来时间尚不清楚。AMD 的 CPU 路线图幻灯片将于 2024 年结束,因此这些内核将在 2024 年首次亮相。
AMD 配备3D V-Cache的 Zen 3 内核已经与我们目前最好的游戏 CPU锐龙 7 5800X3D和Milan-X处理器一起上市。这些芯片通过创新的混合键合工艺将一大块 SRAM 融合在其计算芯片上。AMD 表示,3D V-Cache 芯片将成为其芯片系列中某些战略产品的固定装置,但他们并未承诺为任何特定系列提供任何特定数量的 SKU。
Zen 4c 和 Zen 5c 内核在概念上类似于我们在 Arm 和 x86 风格的其他类型芯片架构中看到的效率内核(e 内核)。AMD 将使用这些内核来制造针对高线程云工作负载进行优化的超密集服务器芯片。AMD 今天还透露,“c”内核支持多线程,因此即将推出的采用 Zen 4c 内核的 EPYC Bergamo 芯片将配备惊人的 128 个内核和 256 个线程。
这些“c”核心比将在热那亚首次亮相的标准 Zen 4 核心更小,删除了某些不需要的功能以提高计算密度。这些芯片具有密度优化的缓存层次结构以增加核心数量,从而解决需要更高线程密度的云工作负载。这可能意味着芯片的缓存更小,或者缓存级别已被删除,但 AMD 尚未分享详细信息。Zen 'c' 内核支持完整的 Zen 4 ISA——与英特尔对 Alder Lake 所做的不同,AMD 不会禁用 AVX 等某些功能。
 AMD 宣布其 Zen 5 架构将于 2024 年上市。由于对微架构进行了全新的重新设计,我们可以期待 Zen 5 比我们在 Zen 4 中看到的更显着的世代改进。如您所料,AMD 旨在提高设计的性能和效率。AMD 表示,它通过利用重新流水线的前端和增加问题宽度来实现这些目标。
AMD 宣布其 Zen 5 架构将于 2024 年上市。由于对微架构进行了全新的重新设计,我们可以期待 Zen 5 比我们在 Zen 4 中看到的更显着的世代改进。如您所料,AMD 旨在提高设计的性能和效率。AMD 表示,它通过利用重新流水线的前端和增加问题宽度来实现这些目标。
AMD 还指出了集成的人工智能和机器学习优化,这可以作为对更新数字格式或矩阵乘法单元的硬件支持。正如预期的那样,这些早期的细节相当简陋。
无限架构使 AMD 早期采用基于小芯片的架构成为可能。这种互连将小芯片、内存和 I/O 芯片连接在一起,AMD 甚至使用它来连接加速器,如其 GPU,用于数据中心应用程序。总体 Infinity 架构是该公司芯片制造工具箱的关键组件,可以将小芯片和其他组件连接在一起。现在,AMD 计划扩大范围并添加支持其最近收购的 Xilinx IP 的扩展。AMD 还将支持来自第三方供应商的 IP,从而使其能够获得更广泛的添加剂。
CXL是一种行业标准的高速缓存一致性互连,它在 CPU 和其他设备(如 GPU、FPGA 和内存设备)之间提供接口。AMD 于 2019 年加入了广泛支持的 CXL 联盟,现在将通过其第四代无限架构支持基于 CXL 2.0 的内存。这意味着我们将看到AMD 处理器支持的三星 512GB CXL 内存扩展器等设备,可能专门用于数据中心。AMD 还计划支持 CXL 3.0。
去年,AMD 还加入了 Universal Chiplet Interconnect Express (UCIe)联盟。UCIe 旨在通过开源设计标准化小芯片之间的芯片到芯片互连,从而降低成本并培育更广泛的经过验证的小芯片生态系统。AMD 重申了其对未来无限架构迭代的 UCIe 标准的承诺。
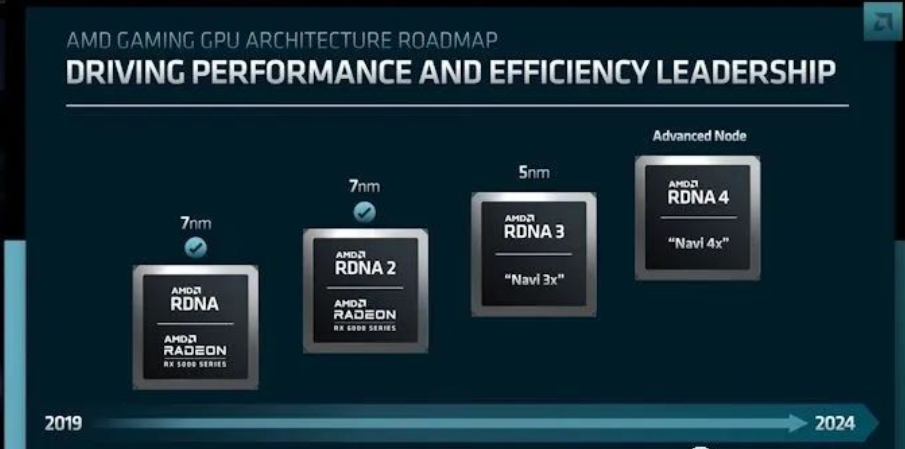
所有这些工具使 AMD 在基于小芯片的产品方面处于领先地位,目前市场上已有 50 多种产品。行业标准互连的添加肯定会扩大公司的范围,特别是当它选择集成来自外部供应商的小芯片时。在 AMD 今天围绕 2022 年金融分析师日发布的一系列公告中,该公司提供了对其客户端 GPU (RDNA) 路线图的更新。就像公司的 Zen CPU 架构路线图一样,AMD 一直在这里保持 2 年的视野,基本上展示了已经发布的内容、即将发布的内容以及一两年内将发布的内容。这意味着今天的更新让我们第一次看到了 RDNA 3 之后的内容,RDNA 3 本身早在 2020 年就宣布了。随着 AMD 凭借其当前的 RDNA 2 架构产品(Radeon RX 6000 系列)取得成功,该公司希望在转向推出基于即将推出的 RDNA 3 架构的产品时保持这一势头。尽管今天 AMD 的路线图更新是高级别的,但它仍然为我们提供了迄今为止最详细的信息,以了解 AMD 在今年晚些时候为其 Radeon 产品存储的内容。首先,与 RDNA 2 相比,AMD 的目标是每瓦性能提升超过 50%。这与他们看到的从 RDNA (1) 到 RDNA 2 的提升类似,虽然 AMD 的这种说法会两年前看起来很炫耀,RDNA 2 为 AMD 的 GPU 团队重新树立了重要的信誉。值得庆幸的是,AMD 与 1 到 2 的过渡不同,他们不必仅根据架构和 DVFS 优化找到一种方法来实现 50% 的提升。RDNA 3 将基于 5nm 工艺(毫无疑问是台积电),这是对基于台积电 N7/N6 的 Navi 2x GPU 系列的全节点改进。因此,仅此一项,AMD 就会看到显着的效率提升。但话虽如此,如今单节点跳跃本身无法提供 50% 的每瓦性能提升(RIP Dennard 缩放)。因此,RDNA 3 计划进行几项架构改进。这包括下一代 AMD 的片上 Infinity Cache,以及 AMD 所说的优化图形管道。据该公司称,GPU 计算单元 (CU) 也在重新架构,但具体程度还有待观察。但在这方面最大的消息是,证实了一年的谣言和几项专利申请,AMD 将使用带有 RDNA 3 的小芯片。AMD 没有说到什么程度,但暗示至少有一个GPU 层(如我们所知)正在从单片 GPU 转变为使用多个较小芯片的小芯片式设计。在某些方面,小芯片是 GPU 构建的圣杯,因为它们为 GPU 设计人员提供了将 GPU 扩展至超过当今裸片尺寸(光罩)和良率限制的选项。也就是说,它也是一个圣杯,因为必须在 GPU 的不同部分之间传递的大量数据(大约 TB 每秒)很难做到——如果你想要一个多芯片 GPU 能够将自己呈现为单个设备。我们已经看到 Apple 基本上通过将两个 M1 SoC 桥接在一起来完成这项任务,但以前从未使用高性能 GPU 完成过。值得注意的是,AMD 将其称为“高级”小芯片设计。当使用某种先进的高密度互连(例如 EMIB)对芯片进行封装时,这个绰号往往会被抛弃,这使其与 Zen 2/3 小芯片等更简单的设计区分开来,后者仅通过有机封装路由信号没有任何增强的技术。因此,尽管我们急切地等待 AMD 在这里所做的更多细节,但发现 AMD 正在使用一种本地硅互连 (LSI) 技术(例如用于MI200 系列加速器)直接和紧密地桥接两个 RNDA 3 小芯片。RDNA 4:在 2024 年进一步提升 AMD 的性能和效率
虽然 AMD 准备将基于 RDNA 3 的 GPU 推向市场,但该公司已经在努力开发其继任者。恰如其名的 RDNA 4 将成为 AMD 2024 年的下一代 GPU 架构。与今天的 Zen 5 发布不同,我们在这里几乎没有得到任何细节——尽管 2020 年发布的 RDNA 3 也是如此。因此,除了名称之外,目前没有太多关于架构的剖析。我们所知道的一件事是,RDNA 4 GPU 将在 AMD 所谓的“高级节点”上制造,这将使其超出用于 RDNA 3 的 5nm 节点。AMD 在 2020 年对 RDNA 3 进行了类似的混淆披露,和当时的情况一样,AMD 似乎为稍后做出最终决定敞开大门,届时 2024 年时间框架的晶圆厂状态将得到更好的确定。TMSC 的 3nm 节点之一将是这里最理想的结果,但 4nm 节点并没有被排除在外——特别是如果 AMD 必须为容量而战。(与消费级 GPU 一样酷,其他类型的产品往往在 mm2 的基础上更有利可图)最后,与 AMD 的 Zen 5 架构一样,RNDA 4 预计将在 2024 年登陆。随着 AMD 近年来建立了相当一致的两年 GPU 节奏,2024 年下半年推出并不是一个不合理的猜测。尽管距离 2024 年还有很长的路要走。








 15010805977
15010805977
 15010876190
15010876190
